REST communication best practices
In this article, you will find information on:
high levelgood practices during microservice integration. You will not find examples or long description, because all of them are a good subject for independent article or chapter in the book.
Introduction
The IT industry moved into a microservice architecture.
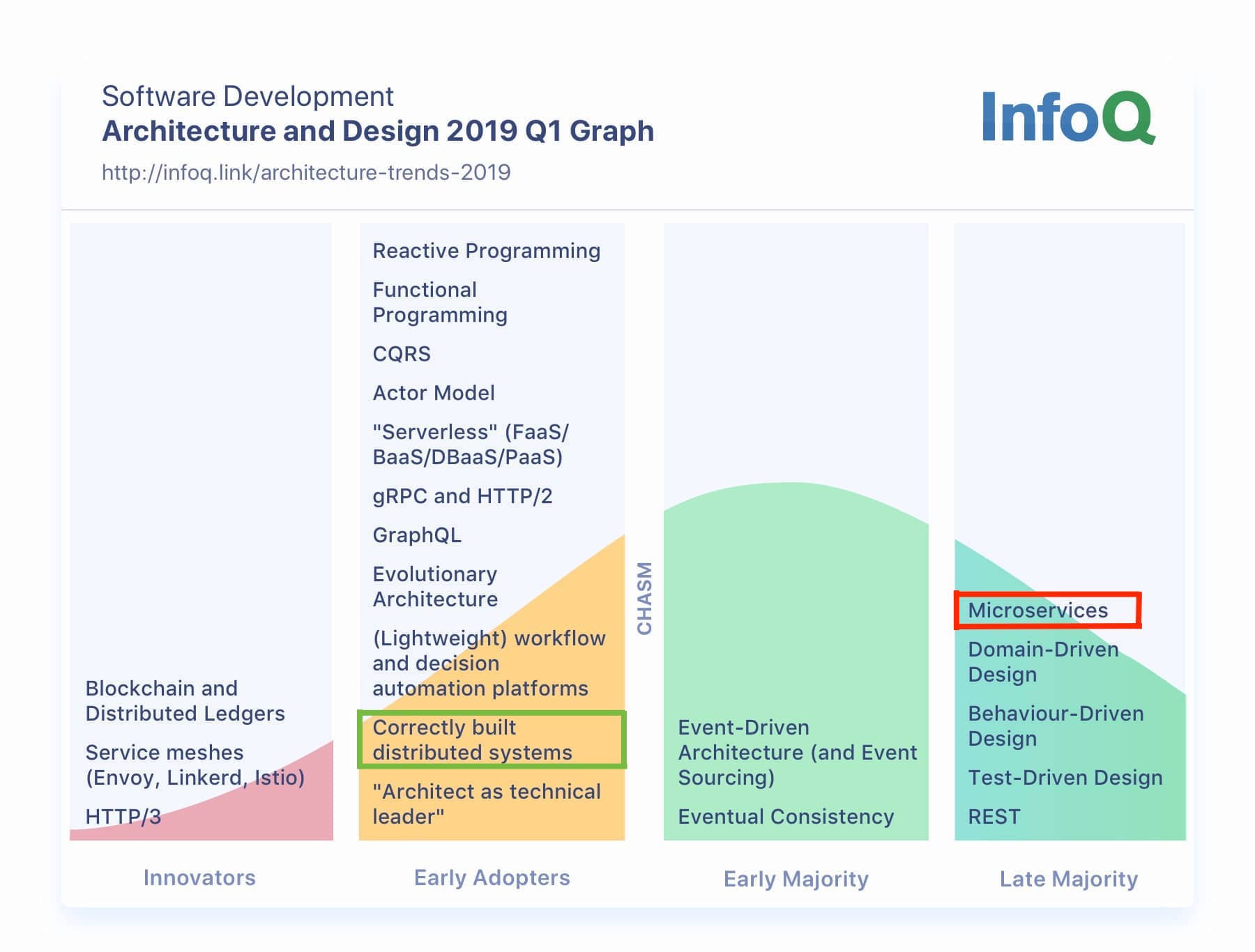
InfoQ publishes an opinionated view about the adoption rate of many technologies.
In the architecture and design for 2019 Q1, we can see that microservices are used by Late majority - 80-90% of people.
In the same diagram, you can see that only Early Adopters do Correctly build distributted system - ~15% of people.
I see a lot of people struggle with the basics mechanisms of communication of microservices, like:
- Some parts of the system may be always broken. We need to accept it and build a system to be resistant to it. Small failures cannot take down the whole platform.
- There are many issues with REST communication.
REST timeout problems
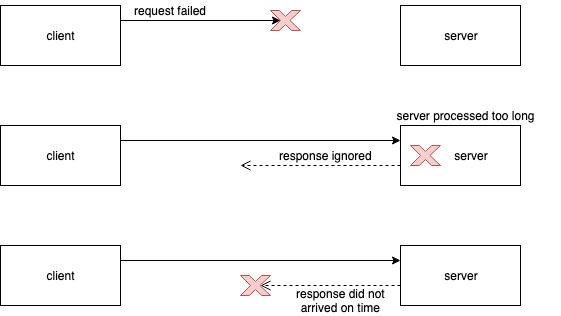
The main problem of REST communication is that we don’t know what is happing when we have a timeout problem. It can timed out because:
- request could never reach the server,
- request reaches the server but was processed too long. Here we don’t know what was the result of request. Was the database transaction committed? A client just got timeout.
- request was processed successfully, but it took too much time to sent a response.
The problem is that you have no idea with a scenario just happened. You can’t know that.
Asynchronous communication
Whenever it is possible, use asynchronous communication between services, e.g. queues/streams. Advantages:
- You eliminate a lot of problems with synchronous communication like timeouts, internal server error, etc.
- If your service cannot handle big traffic, you can consume events in the speed that is appropriate for your service.
Disadvantages:
- You need to prepare a system for deduplication of messages (in synchronous communication as well). It can happen that the same message will be provided more than once (at-least-once delivery).
- You need to guarantee delivery of the asynchronous messages. In many situations you can end up with two-phase commit problem, for example: write something in DB and emit an event.
- Most of the systems have some kind of message hospital to fix problems with messages that failed.
Idempotency
When we send the request and receive timeout, we are not sure what happened. Maybe we got a temporary network problem, maybe the server was just too slow. The natural solution would be a retry of action. In this case, the server needs to be ready for it (I don’t want to send the email twice or buy two items in the shop). The server need to be able to discover that given request has been made in the past and return:
- HTTP status that will let us know about it, for example I personally return
409 Conflictbecause it tells me that a given resource already exists. If you can find a better code it is fine. Just make sure to document it in your contract documentation (e.g. OpenApi) - body the same as for successful request, so the client is able to read returned values.
Retry
When the request was not successful, retry can be a natural solution. With a retry mechanism, you need to be careful. It is not a golden hammer. Imagine that a server has a performance problem. By retrying you can make the situation even worse. Also, think about a retry strategy. Maybe you want to retry at the same time intervals or with exponential intervals. Another question is how many times you should retry? All the parameters you need to adjust to the service that you call.
Circuit breaker
If you write a classical thread-based web application, every HTTP call is blocking your thread. If you call another system and it is very slow, you can get a timeout.
Then the frustrated users can click retry again and again. Your application will send more and more requests - that will make the situation bad everywhere - your threads will wait for a response and the external system will get more requests to process.
The natural solution would be to stop sending requests until service recover. To not kill our application, it would be better to fail fast.
Circuit breaker is a pattern that makes is possible. When the server fails too often, a circuit opens and values are taken from fallback either request fails fast. When server recover, a circuit closes and requests are being sent in standard way.There is multiple implementation in Java, for example:
Async
Solution for timeouts in communication can we switch to async frameworks which do not depend on threads and do not suffer when a call takes a lot of time:Example of frameworks:
The main blocker is a database, while R2DBC driver is not production-ready.
State handling
When you execute some logic in database transaction it is easy to rollback everything when something failed. It became more complicated in distributed systems with distributed transactions. When your system calls successfully Service A, but failed during the call of Service B, we may leave the system in a bad state.
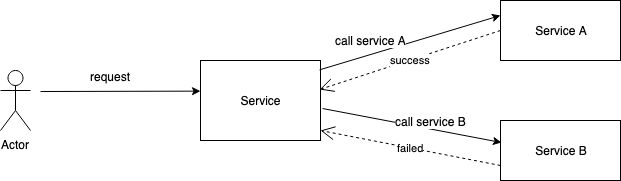
Solution for it is to manage the state of distributed transactions like:
- SAGA pattern. In this case your REST service need to expose compensations for every action.
- SEDA - Staged event-driven architecture in asynchronous world. In many cases solution would be state machine or BPM process.
Timeout
Maybe it sounds trivial, but make sure that you set timeouts:
- connection - timeout in making the initial connection; i.e. completing the TCP connection handshake,
- read - timeout on waiting to read data.
Monitoring
Whatever you do: synchronous or asynchronous communication, you should make proper monitoring, at least of most important indicators:
- How many times do you try to communicate with other services,
- How much time does successful/unsuccessful communication takes (remember that average time is not so meaningful, maybe you want to see 90%, 99%, etc. )
- If you are a server, try to know your clients and measure load generated by them.
Summary
Monolithic applications were much easier to design and have fewer problems with communications. We sacrificed the simplicity od monolith for the scalability of microservices. When we do it, we cannot forget about many pitfalls that are lurking in microservices integrations.
In this article I propose many mechanism of making integration more stable. I am sure you know more, let me know in comments !