PostgreSQL 10 table partitioning
In this article, you will find information on:
- What is partitioning
- How to implement partitioning
- Which problems I found using PostgreSQL 10 table partitioning.
Example of the working Java/SQL code you can find here.
Overview
Table partitioning refers to splitting what is logically one large table into smaller physical pieces.
Methods of partitioning
There are two methods of data partitioning:
- Horizontal partitioning (involves putting different rows into different tables) - covered in this article.
- Vertical partitioning (involves creating tables with fewer columns and using additional tables to store the remaining columns) - not covered in this article.
Benefits of partitioning
- Your SQL search and update query performance can be improved dramatically (smaller table needs to be scanned, smaller index needs to be rebuilt).
- Bulk loads and deletes can be accomplished by adding or removing partitions.
- Seldom-used data can be migrated to cheaper and slower storage media.
- For frequently-used data, you can create sub-partitions or composite partitions.
Types of horizontal partitioning
There are two built-in partitioning types:
- Range partitioning - The table is partitioned into “ranges” defined by a key column or set of columns, with no overlap between the ranges of values assigned to different partitions. For example, one might partition by date ranges or by ranges of identifiers for particular business objects.
- List Partitioning - The table is partitioned by explicitly listing which key values appear in each partition.
PostgreSQL 9 vs PostgreSQL 10 partitioning
Partitioning in PostgreSQL 9 was a nice improvement. Unfortunately, for Hibernate developers, it couldn’t be transparent. It required triggers that would put a row in the proper partition table. The problem was that it didn’t return the id of the inserted row and it couldn’t be mapped by Hibernate in a standard query. PostgreSQL 9 solution is faster than PostgreSQL 10 partitioning, but less convenient.
Implementing Partitions
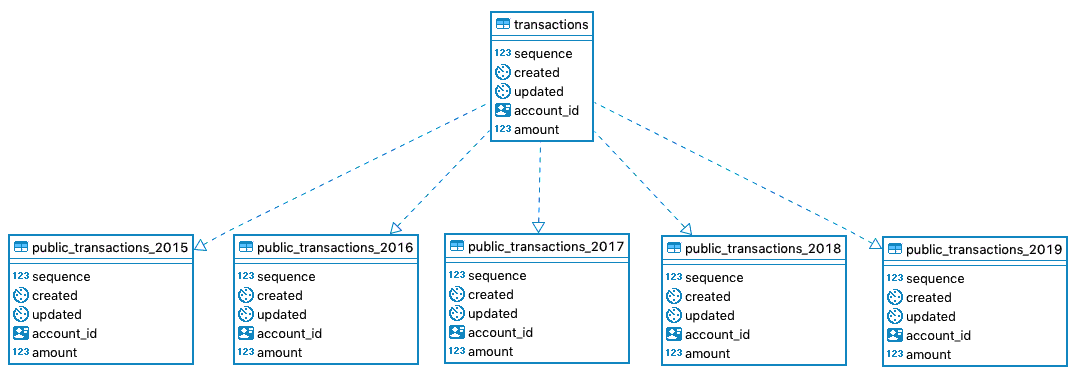
- Create the “master” table.
-- sequence will allow keeping the order of rows in all tables CREATE SEQUENCE global_sequence START WITH 1 INCREMENT BY 10 NO MINVALUE NO MAXVALUE CACHE 1; # CREATE TABLE transactions ( sequence BIGINT DEFAULT nextval('global_sequence'::regclass) NOT NULL, -- default value on created and updated so you can skip trigger for it created TIMESTAMP WITHOUT TIME ZONE NOT NULL DEFAULT clock_timestamp(), updated TIMESTAMP WITHOUT TIME ZONE NOT NULL DEFAULT clock_timestamp(), account_id UUID NOT NULL, amount NUMERIC NOT NULL ) PARTITION BY RANGE (created); - Create partitions.
CREATE TABLE transactions_2015 PARTITION OF transactions FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2016-01-01 00:00:00'); # CREATE TABLE transactions_2016 PARTITION OF transactions FOR VALUES FROM ('2016-01-01 00:00:00') TO ('2017-01-01 00:00:00'); # repeat for each partition table. - Create foreign keys on column(s) in each partition.
ALTER TABLE ONLY transactions_2015 ADD CONSTRAINT transactions_2015_account_id_fkey FOREIGN KEY (account_id) REFERENCES accounts(id) ON UPDATE RESTRICT ON DELETE RESTRICT; # ALTER TABLE ONLY transactions_2016 ADD CONSTRAINT transactions_2016_account_id_fkey FOREIGN KEY (account_id) REFERENCES accounts(id) ON UPDATE RESTRICT ON DELETE RESTRICT; # repeat for each partition table. - Create an index on the key column(s) in each partition.
CREATE INDEX ON transactions_2015 (account_id); CREATE INDEX ON transactions_2016 (account_id); # repeat for each partition table. - Create triggers in each partition.
CREATE TRIGGER set_updated_trigger BEFORE INSERT OR UPDATE ON transactions_2015 FOR EACH ROW EXECUTE PROCEDURE public.set_updated(); # CREATE TRIGGER set_updated_trigger BEFORE INSERT OR UPDATE ON transactions_2016 FOR EACH ROW EXECUTE PROCEDURE public.set_updated(); # repeat for each partition table.
Partition limitations in PostgreSQL 10
The main limitations are:
- No global unique constraint (you can create it only on partition table level, not on master partition level);
- No global row triggers, indexes;
- No global primary and foreign keys;
- No auto-creation of new partitions;
- No update moves rows across partitions (you need to delete a row from one partition and create it in another);
- Not possible to turn a regular table into a partitioned table or vice versa.
Global Uniqueness
Partitioned tables cannot yet be referenced by foreign constraints. This is due to the lack of global indexes (a.k.a. single indexes across all partitions) and has a profound impact on the design of a database: rendering it impossible to ensure global value uniqueness across all partitions, whether on a primary key or on a unique constraint.
Global indexes will be introduced in PostgreSQL 11, and in the meantime, the following three workarounds are the only viable ones:
- Have a secondary non-partitioned table where the unique constraints are defined and that only contains the columns involved in those constraints.
- If there are no concurrency concerns, let the application check beforehand for the existence of an entry with the same key before insertion (scan of the table aided by partition routing and proper indexes defined on the single partitions). This works only with isolation
READ COMMITTEDlevel. - If there are concurrency concerns and there is a guarantee that uniqueness could only be violated within one account (or user), another table that contains all accounts could be used for locking this particular account with
SELECT FOR UPDATEfor the duration of the transaction. This also works only with isolationREAD COMMITTEDlevel.SELECT FOR UPDATEcan’t be normally used on the partitioned table, because the row that needs to be locked may not exist.
Unfortunately, all of these approaches partially invalidate the gains in terms of the performance and scalability introduced by partitioning, but it will at least lay the foundations for a proper design to be improved once PostgreSQL 11 is available.
Useful advice
- Do not go overboard with partitioning, only important tables.
- Do it table by table.
- Test partitions with integration tests (check whether a row is in a proper partition).
- The popular idea for partitioning is DATETIME and having BIGINT as a primary key. From a theoretical point of view, it is possible that the last row in the older partition will have a higher primary key than the first row in the newer partition. It is a good idea to add an additional constraint on the partition on the primary key when you stop actively write to partition.
When to do partitioning
For the question: how many rows should my table contain to partition it?
I always hear: It depends.
But if I need to give some magic number, I would say: 10 million in the whole history of the table.
PostgreSQL 11 features
PostgreSQL is planned for release in autumn 2018. Here is a full list of the most important features from a partitioning point of view:
- Update Moves Rows Across Partitions
- Unique index on the master table
- Default Partition table
- Partition by Hash
CREATE TABLE my_table (some_field text) PARTITION BY HASH (some_field); CREATE TABLE my_table_0 PARTITION OF my_table FOR VALUES WITH (MODULUS 3, REMAINDER 0);
Alternative solutions
As an alternative to partitioning, you may consider using sharding or both: partitioning and sharding.
Summary
Partitioning in PostgreSQL 10 allows Java developers (Hibernate users) to easily and transparently map partitioned tables to a Java object. It still has some drawbacks, like repeated code to create indexes, foreign keys, etc. PostgreSQL 11 seems to be a nice improvement. The release cycle of Postgres is speeding up, so the new version will be available soon.