Concurrent calls
In this article, you will find information on:
- how to handle two concurrent calls.
Problem description
I met the problem when a two concurrent HTTP calls need to create some operations for an account (with a unique index on a field id). If an account was not present, it needs to be created.
There are two cases:
- The account exists. Then two calls create operation for it.
- The account doesn’t exist. Than two concurrent calls need to create an account and operations associated with it. One of the calls will fail, because of violating the uniqueness of
UNIQUE constraint. Additionally, all inserted operations for one account needed to be executed in order calls.
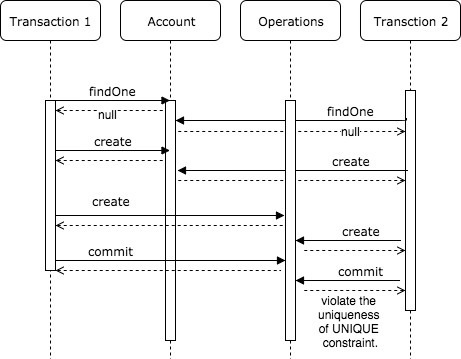
INSERT ON CONFLICT DO NOTHING
Before I came to the solution, I will quickly describe a syntax of the INSERT ON CONFLICT DO NOTHING.
There is PostgreSQL syntax INSERT ON CONFLICT DO NOTHING. It means do nothing if the row already exists in the table. Syntax:
INSERT INTO Accounts (id, … ) VALUES(...) ON CONFLICT (id) DO NOTHING
The query will not fail if account.id existed before.
SELECT FOR UPDATE
SELECT FOR UPDATE statement is a locking mechanism. Other transaction cannot read the row before current transaction finish.
I described it in detals in this article
Solution
The operation can be described in the SQL pseudocode:
BEGIN TRANSACTION
SELECT * FROM ACCOUNTS FOR UPDATE WHERE ID = {id}
IF(result_of_select == null) {
INSERT INTO ACCOUNTS (id, ..) VALUES (...) ON CONFLICT DO NOTHING
COMMIT
BEGIN TRANSACTION
SELECT * FROM ACCOUNTS FOR UPDATE WHERE ID = {id}
}
INSERT OPERATIONS
COMMIT
There are two cases:
1) There was an account in DB. Then the statement simplify to the form:
BEGIN TRANSACTION
SELECT * FROM ACCOUNTS FOR UPDATE WHERE ID = {id}
INSERT OPERATIONS
COMMIT
so we lock the account and insert operations associated with the account.
2) The account doesn’t exist. Then we have another form:
BEGIN TRANSACTION
SELECT * FROM ACCOUNTS FOR UPDATE WHERE ID = {id}
INSERT INTO ACCOUNTS (id, ..) VALUES (...) ON CONFLICT DO NOTHING
COMMIT
BEGIN TRANSACTION
SELECT * FROM ACCOUNTS FOR UPDATE WHERE ID = {id}
INSERT OPERATIONS
COMMIT
In the first transaction, we insert an account and finish the transaction. If there is a second concurrent transaction, it will try to insert it too, but finally will not do anything. The second transaction is locking an account and insert operations. The concurrent call will wait till this transaction is finished.
Alternative solutions that I tried before
Serializable isolation level
At the beginning, I tried to use the isolation level SERIALIZABE. The solution worked in most cases, but is some cases SQLException was thrown with a description:
ERROR: could not serialize access due to read/write dependencies
among transactions
As a solution, I could handle this exception and repeat operation. Finally, I decided that this isolation level provide some benefits, but also new problems that I don’t want to handle (and SQLException is one of it).
Read committed isolation level + locking table
I decided to write a solution in standard read committed isolation level.
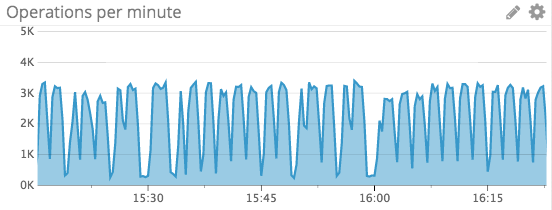
I created a table lock_account with a single, unique column - account_id. At the beginning of transaction insert was made to the table. It was blocking of execution of other transaction for the same account. Another insert to this table was blocked till the end of first transaction, when the row was deleted.
Despite the fact that the solution was working properly, the performance was not satisfying me. The throughput was not constant and vacuuming was using a lot of resources. It is because PostgreSQL marked deleted row as deleted and later it need to be removed.
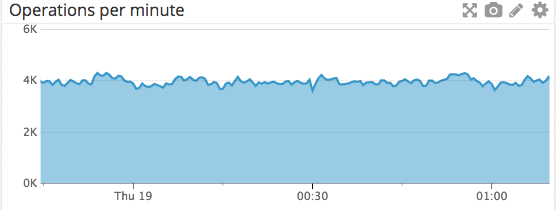
Here you can see comparison of my final solution versus version with locking table:
Summary
Database locking can enable to make concurrent calls in efficient way without any exceptions with satisfying performance.